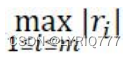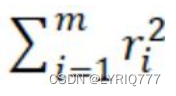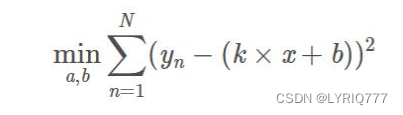ʲô�Ǿ��Իؚw��
���Իؚw��Linear regression����һ�N���þ��Ժ�������׃��������������׃��֮�g���Pϵ�M�н�ģ�ķ��������Իؚw�ǙC���W����һ�N�V��ʹ�õĻ����ؚw�㷨�������ж��������ľ��Իؚw�Q���Ԫ���Իؚw��
���� ���O�� nn ����������׃����x1x1,x2x2,...,xnxn��һ��ݔ��׃�� yy�����Իؚw��һ����ʽ��ʾ���£�
y=f(x)=w1x1+w2x2+...+wnxn+b .(1)(1)y=f(x)=w1x1+w2x2+...+wnxn+b .
���У�ϵ�� w1w1,w2w2,...,wnwn �������ę��أ�bb ��ƫ�á�
��ʽҲ���Ԍ�����������ʽ��y=f(x)=wTx+b .(2)(2)y=f(x)=wTx+b .
����x=[x1,x2,...,xn]x=[x1,x2,...,xn],w=[w1,w2,...,wn]w=[w1,w2,...,wn].
�������ɣ���Ҳ��������ֱ���ψD���ЈD�����ࡣ
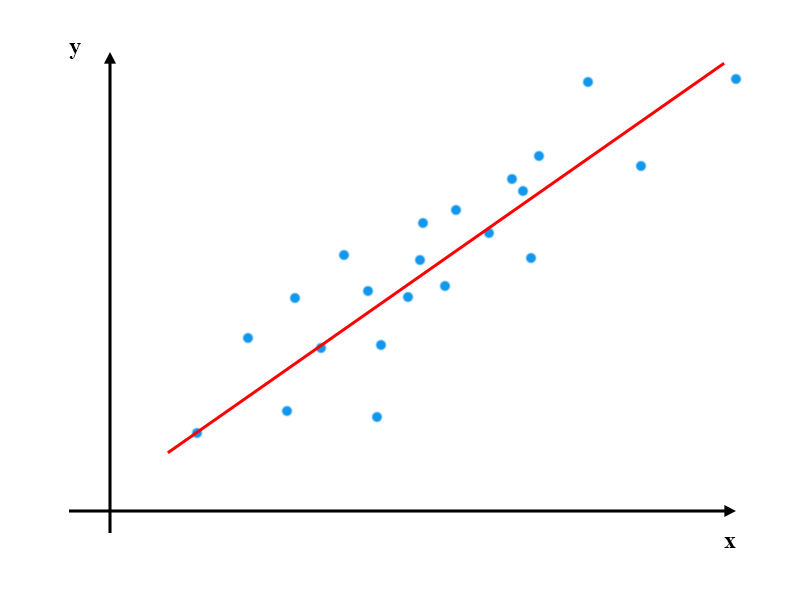
�{ɫ��ʾ�����c���tɫֱ����ʾ��K��õľ��Իؚw�Y����
�N���Իؚw�㷨��
��С���˷���
• ��ͨ�^ ��С���`���ƽ���� �����Ҕ�������Ѻ���ƥ�䡣
• ������С���˷����Ժ�������δ֪�Ĕ�������ʹ���@Щ��õĔ����c���H����֮�g �`���ƽ�� �� ����С��
• ���O�҂��F����һϵ�еĔ����c(xi,yi) (i=1,…,m)����ô���҂��o���ĔM�Ϻ���h(x)�õ��Ĺ�Ӌ������h(xi)
• ���ri = h(xi) – yi
• ���N������
1. ∞-����������^��ֵ�����ֵ�������Д����c�К�����x�����ֵ��
2. 1-�������^������ͣ������Д����c������x֮�ͣ�
3. 2-����������ƽ���ͣ�
• �M�ϳ̶ȣ���ͨ��Ԓ���v�������҂��ĔM�Ϻ���h(x)�c�����ĺ���y֮�g�������ԡ���ô
2-����ԽС����Ȼ�����Ծͱ��^���ˡ�
����ʽ�ӾͿ��Ԍ��飺
�քe��k��b��ƫ����Ȼ����ƫ������0�����ɫ@�ØOֵ�c��
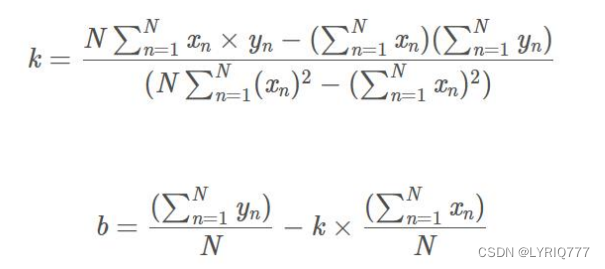
RANSAC��
• �S�C�ɘ�һ���ԣ�random sample consensus����
• RANSAC��һ�N˼�� ��һ�������֪ģ�͵ą����Ŀ�ܡ� ������ijһ�ض��Ć��}��������Ӌ ��Cҕ�X�Ć��}��ͬ��Ҳ�����ǽyӋ���W�����������ǽ����W�I���ģ�ͅ�����Ӌ���}��
• ����һ�N�����ķ������Á���һ�M�����xȺ�ı��^�y�����й�������Wģ�͵ą����� RANSAC��һ���Ǵ_�����㷨����ij�N���x���f�������a��һ����һ�������º����ĽY���������Sʹ�ø���εĵ�����ʹ��������ӡ�
• RANSAC�Ļ������O�� “��Ⱥ”��������ͨ�^�Mģ�ͅ����픢���䔵���ֲ�����“�xȺ”�����t�Dz��m��ģ�ͻ��Ĕ����� ����������Ӱ�,��ָ�����xȺ������ĘO�˵������e�`������P�����Ĝy�������_�ļ��O�� RANSAC�ٶ����o��һ�M��ͨ����С�ģ���Ⱥ������һ�� �����@��������Թ�����ѽ�ጻ����m�����@һ����ģ�͵ą�����
RANSAC�㷨��ݔ��:
1. һ�M�^�y���������������^�������oЧ�c����
2. һ�����ڽ���^�y�����ą�����ģ�ͣ� ���� y=ax+b
3. һЩ���ŵą�����
RANSAC �IJ��E��
1. �ڔ������S�C�x��ׂ��c�O�����Ⱥ
2. Ӌ���m�σ�Ⱥ��ģ�� e.g. y=ax+b ->y=2x+3 y=4x+5
3. ���������ś]�x�����c���넂�Ž�����ģ���У�Ӌ���Ƿ���Ⱥ e.g. hi=2xi+3->ri
4. ӛ��Ⱥ����
5. �؏����ϲ��E
6. ���^�Ĵ�Ӌ���Ѓ�Ⱥ�������,��Ⱥ�����Ǵ�������ģ�;����҂���Ҫ��Ľ�
ע�� �� ��ͬ���}�����Ĕ��Wģ�Ͳ�ͬ�������Ӌ��ģ�ͅ����r�����ض���ͬ��RANSAC�����ò�����
Ӌ��ģ�ͅ��������@����ransac��ȱ�c����Ҫ�Wģ����֪��
�@���Ўׂ����}��
1. һ�_ʼ�ĕr���҂�Ҫ�S�C�x������c(n)
2. �Լ�Ҫ�؏������ٴ�(k)
• ���Oÿ���c��������Ⱥ�ĸ��ʞ� w��
w = ��Ⱥ�Ĕ�Ŀ/����Ⱥ��Ŀ+��Ⱥ��Ŀ��
• ͨ���҂���֪�� w �Ƕ���, w^n�����x���n���c���ǃ�Ⱥ�ęC��, 1-w^n �����x���n���c������һ�����ǃ�Ⱥ�ęC��, (1 − w^n)^k �DZ�ʾ�؏� k �ζ��]��ȫ����n���c���ǃ�Ⱥ�ęC��, ���O�㷨�� k ���Ժ�ɹ��ęC����p����ô,
1 − p = (1 − w^n)^k
p = 1 − (1 − w^n)^k
• �҂�����ͨ�^P����õ���ȡ�Δ�K��K=log(1-P)/log(1-w^n)��
• �������ϣ���ɹ��C�ʸߣ�
• ��n��׃�r��kԽ�tpԽ�� ��w��׃�r��nԽ�������k��Խ��
• ͨ��wδ֪������n �xСһ�c���^�á�
RANSAC �ă�ȱ�c��
���c��
1. ���������Ĺ�Ӌģ�ͅ��������磬���İ������������c�Ĕ������й�Ӌ���߾��ȵą�����
ȱ�c��
1. ��Ӌ�ㅢ���ĵ����Δ��]�����ޣ�����O�õ����Δ������ޣ��õ��ĽY�����ܲ�����ĽY�����������ܵõ��e�`�ĽY����
2. RANSACֻ��һ���ĸ��ʵõ����ŵ�ģ�ͣ������c�����Δ������ȡ�
3. ��Ҫ���O�ø����}���P���yֵ��
4. RANSACֻ���ض��Ĕ������й�Ӌ��һ��ģ�ͣ�������ڃɂ����������ģ�ͣ�RANSAC�����ҵ��e��ģ�͡�
5. Ҫ�Wģ����֪
RANSAC �c��С���˷�
• ���a���`�еĔ�����������һ����ƫ�
• �����҂�֪���ɂ�׃��X�cY֮�g�ʾ����Pϵ��Y=aX+b���҂���_������a�cb�ľ��wֵ��ͨ�^�����Եõ�һ�MX�cY�Ĝyԇֵ���mȻ��Փ�σɂ�δ֪���ķ���ֻ��Ҫ�ɽMֵ���ɴ_�J��������ϵ�y�`���ԭ������ȡ���c�����a�cb��ֵ�����M��ͬ���҂�ϣ�����ǣ����Ӌ��ó�����Փģ���c�yԇֵ���`����С��
• ��С���˷���ͨ�^Ӌ����С�������P�څ���a��b��ƫ��������r��ֵ�����ϣ��ܶ���r�£���С���˷����Ǿ��Իؚw�Ĵ����~��
• �z�����ǣ���С���˷�ֻ�m�����`���^С����r��
• ��ģ�ʹ_���Լ��������Δ����S����r�£�RANSAC�������ҵ���⡣�����ڰ���80%�`��Ĕ�������RANSAC��Ч���h����ֱ�ӵ���С���˷�����
• ����һ���DƬ�������c����������С���˷��\������Ӌ���ٶ�����
��ϣ�㷨��
1. ��ֵ��ϣ�㷨aHash
���E
1. �s�ţ��DƬ�s�Ş�8*8�������Y������ȥ������
2. �ҶȻ����D�Q��ҶȈD��
3. ��ƽ��ֵ��Ӌ��ҶȈD�������ص�ƽ��ֵ��
4. ���^������ֵ����ƽ��ֵӛ��1���෴ӛ��0������64λ��
5. ����hash�����������E���ɵ�1��0�����M���������LjDƬ��ָ�y��hash����
6. ����ָ�y�����ɷ��D��ָ�y���ȣ�Ӌ��h�����x�����ɂ�64λ��hashֵ�ж���λ�Dz�һ�ӵģ�����ͬλ��Խ�٣��DƬԽ���ơ�
�h�����x
�ɂ�����֮�g�ĝh�����xָ�����@�ɂ����������M��λ��ͬ��λ�õĔ�Ŀ��
2. ��ֵ��ϣ�㷨dHash
��ֵ��ϣ�㷨���^�ھ�ֵ��ϣ�㷨��ǰ�ںͺ��ڻ�����ͬ��ֻ�����g���^hash��׃����
���E
1. �s�ţ��DƬ�s�Ş� 8*9 �������Y������ȥ������
2. �ҶȻ����D�Q��ҶȈD��
3. ��ƽ��ֵ��Ӌ��ҶȈD�������ص�ƽ��ֵ�� ---�@���]�У�ֻ�Ǟ����c��ֵ��ϣ������
4. ���^������ֵ���ں�һ������ֵӛ��1���෴ӛ��0�����в��c��һ�Ќ��ȣ�ÿ��9�����أ�
�˂���ֵ����8�У�����64λ
5. ����hash�����������E���ɵ�1��0�����M���������LjDƬ��ָ�y��hash����
6. ����ָ�y�����ɷ��D��ָ�y���ȣ�Ӌ��h�����x�����ɂ�64λ��hashֵ�ж���λ�Dz�һ�ӵģ�����ͬλ��Խ�٣��DƬԽ���ơ�
3. ��֪��ϣ�㷨pHash
��ֵ��ϣ�㷨�^�ڇ����_�����m�������s�ԈD�����˫@�ø����_�ĽY�������x���֪��ϣ
�㷨�������õ���DCT���xɢ����׃�Q���������l�ʵķ�����
���E��
1. �sС�DƬ��32 * 32��һ���^�õĴ�С���@�ӷ���DCTӋ��
2. �D����ҶȈD���ѿs�ź�ĈDƬ�D����ҶȈD��
3. Ӌ��DCT:DCT�шDƬ���x�ɷ��ʵļ���
4. �sСDCT��DCTӋ���ľ����32 * 32���������Ͻǵ�8 * 8���@Щ����DƬ������l�ʡ�
5. Ӌ��ƽ��ֵ��Ӌ��sСDCT������������c��ƽ��ֵ��
6. �Mһ���pСDCT������ƽ��ֵӛ䛞�1����֮ӛ䛞�0.
7. �õ���Ϣָ�y���M��64����Ϣλ������S�Ᵽ��һ���ԡ�
8. ���Ȍ��ɏ��DƬ��ָ�y���@�Ýh�����x���ɡ�
�xɢ����׃�Q DCT
|