�ڙC���W���Լ���ȌW�����҂��������������t���@һ���~������͜\Մһ��ʲô�����t�����Լ����t�������x���ڣ�
һ��ʲô�����t����
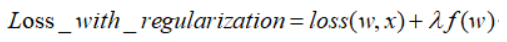
���t��� (�ַQ���P�)�����P����ģ�͵ą�������ֵ����ؓ
λ�����t��ϵ������һ�����������{�����P�����ȣ�Խ��t���P����Խ��
�������t����Ŀ�ģ�
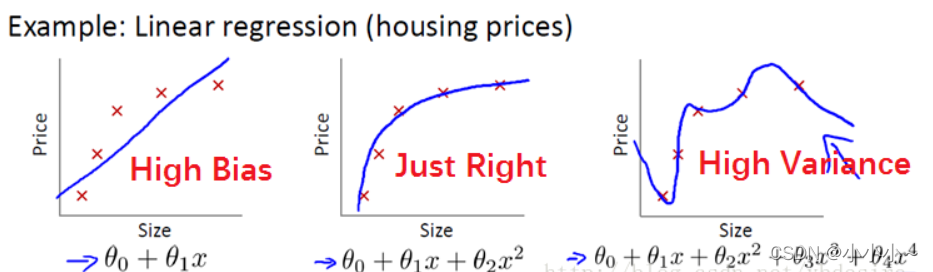
���ψD��
�ψD���������Ξ飺Ƿ�M�ϡ������B���^�M��
Ƿ�M�Ϗ�������˼��������Ƿȱ�M�ϳ̶ȣ��@һ���ڏ��s�Ⱥܵ͵�ģ���г��F���Ĕ��W�ρ�����һԪһ�κ�����һ�lֱ����һԪ���κ�����һ���������Դ���ơ���ô����Խ�࣬��Խ�ܔM�ϸ����s������������һζ������ģ�͵ď��s�Ⱦ͕�����^�M�ϬF��һ���^�M�ϣ�ģ�͵ķ��������Լ������Ԍ��e���ô��ô�Y���^�M�ϬF���أ�
�ڏĔ��W����������������˜pС�^�M�ϣ�Ҫ��һ���օ����Þ�0����ֱ�^�ķ����������ƅ����Ă�������˿���ͨ�^���t������Q�����pСģ�ͅ�����С�������������^�M�ϡ�
���W�j�����������sigmoid���������D
����҂������t��ϵ����lambda���o�F�t����w�͕�څ����0������׃С�������ݔ��z׃С��z׃С���͵��˼�����ľ��ԅ^�Ķ�������ģ�͵ķǾ��Ի��̶ȡ�
����L1��L2���t��
��һ��L1���t��
L1���t��,�ַQLasso Regression����ָ��ֵ����w�и���Ԫ�صĽ^��ֵ֮�͡����� ����A=[1��-1��3]�� ��ôA��L1������ |1|+|-1|+|3|��
L1���t������һ����������ϵ���sС��0������L1�m��������֮�g���P����r���Ԯa��ϡ���ֵ��ꇣ��ܶ����؞�0���tһЩ�������^�V���������a��һ��ϡ��ģ�ͣ��������������x��L1Ҳ���Է�ֹ�^�M�ϡ�
��ôL1��ʲô���a��һ��ϡ���ֵ����أ�
L1���t���Ǚ�ֵ�� �^��ֵ֮�ͣ�����L1�ǎ��н^��ֵ��̖�ĺ���������Dz���ȫ���ġ��C���W�����΄վ���Ҫͨ�^һЩ�����������ݶ��½�������pʧ��������Сֵ�����҂���ԭʼ�pʧ����������L1���t��헕r���ஔ�ڌ��pʧ��������һ���s����
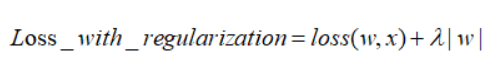
�˕r�҂����΄�׃���ڼs�������ȡ��Сֵ�Ľ⡣���]���S����r����ֻ�Ѓɂ���ֵ�� ���˕r�����ݶ��½�������⺯�����^�̿��Ԯ�����ֵ����ͬ�rL1���t���ĺ���Ҳ�����ڶ��Sƽ���Ϯ����������D��
(1)��������}����
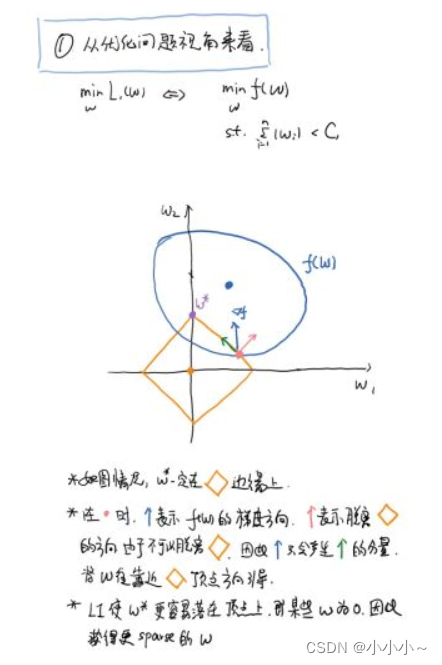
����ĈD���Ǻ�������a�����£�
�D���{ɫ�AȦ����Loss��ǰ�벿�ִ�����헵ĵȸ߾��������f��ͬһ�l������ȡֵ��ͬ����Խ����������ֵԽС��
�Sɫ���΅^����L1���t����ơ��������t����loss���������Ҫ���Sɫ���΅^����{ɫ�AȦ��֮�g���У�Ҳ�����f�����F�ڈD�Ѓ���헵ȸ߾��c���t���^���ཻ̎���ĈD�п��Կ�������������헵ĵȸ߾���u�����t����ƅ^��Uɢ�r��L1���t���Ľ��c����������S�ϣ��t�ܶ������S�����䅢��w��0����˕��a��ϡ��⣻�����t��ǰ���ϵ�������Կ��ƈD�εĴ�С��ԽС���s��헵ĈD��Խ���ψD�е��Sɫ����Խ�s��헵ĈD�ξ�ԽС������С����ɫ����ֻ����ԭ�c����һ�c�c���@����c��ֵ�еĿ���ȡ����С��ֵ��
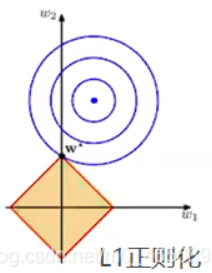
(��)��L2���t��
L2���t����ָ��ֵ�����и���Ԫ�ص�ƽ����Ȼ������ƽ�������������M�ж��μs��������w׃С���������㣬�����γ�ϡ��� ������ʹ������ⷀ�����٣�ʹ����ƽ��������L2�m��������֮�g�]���P����r��
 ���]���S����r����ֻ�Ѓɂ���ֵ�� ���˕r�����ݶ��½�������⺯�����^�̿��Ԯ�����ֵ����ͬ�rL1���t���ĺ���Ҳ�����ڶ��Sƽ���Ϯ����������D�� ���]���S����r����ֻ�Ѓɂ���ֵ�� ���˕r�����ݶ��½�������⺯�����^�̿��Ԯ�����ֵ����ͬ�rL1���t���ĺ���Ҳ�����ڶ��Sƽ���Ϯ����������D��

�D���{ɫһȦһȦ�ľ���Loss��ǰ�벿�ִ�����헵ĵȸ߾��������f��ͬһ�l������ȡֵ��ͬ����Խ����������ֵԽС���D���Sɫ�A�΅^����L2���t����ơ��������t����loss���������Ҫ��loss���������t�֮�g���У�Ҳ�����f�����F�ڈD�Ѓ���헵ȸ߾��c���t���^���ཻ̎���ĈD�п��Կ�������������헵ĵȸ߾���u�����t����ƅ^��Uɢ�rL2���t���Ľ��c����ڷ������S�ϣ����Sƽ����L2���t���ĺ����D���ǂ��A���c������ȣ���ĥȥ����ǡ�����c�ཻ�rʹ�û������ęC��С���S�࣬�@���Ǟ�ʲôL2���t��������ϡ���Ե�ԭ��
�ġ��ɷN���t���IJ�ͬ
��һ�������ݶȷ������
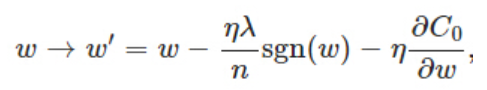

�ψD�քe��(���)L1�����҂ȣ�L2���t���ķ����������
������L1����ԭʼ�ĸ���Ҏ�t�����η ∗ λ ∗ s g n ( w ) / n η * λ * sgn(w)/nη∗λ∗sgn(w)/n�@һ헡���w�����r�����º��w׃С����w��ؓ�r�����º��w׃��——�������Ч������w��0����ʹ�W�j�еę��رM���ܞ�0��Ҳ���ஔ�ڜpС�˾W�j���s�ȣ���ֹ�^�M�ϡ�
������L2���ڲ�ʹ��L2���t���r���Y����wǰϵ����1���F��wǰ��ϵ���� 1 − η λ / n 1−ηλ/n1−ηλ/n �����η��λ��n�������ģ����� 1 − η λ / n 1−ηλ/n1−ηλ/nС��1������Ч���ǜpСw���@Ҳ���Ǚ���˥�p��weight decay�����Ɂ�����Ȼ���]������Č���헣�w��K��ֵ��������Ҳ���ܜpС����С�ę�ֵw����ij�N���x���f����ʾģ�͵ď��s�ȸ��ͣ��������ĔM�τ����ã��@�����tҲ�����W��ķ�굶�������ڌ��H�����У�Ҳ��C���@һ�c��L2���t����Ч����������δ�����t����Ч����
�C�����σɂ�ʽ�ӣ���w ww̎��[ 1 , + ∞ ] [1, +\infty][1,+∞]�r��L2��L1�@�ø���ĜpС���ʣ�����w ww̎��( 0 , 1 ) (0,1)(0,1)�r��L1��L2�@�ø���ĜpС���ʣ����Ү�wԽС��L1�����ӽ���0����L2��������׃�����D�����ĸ�������һЩ��
�����������ʷ������

| 
