1�������Z��������ʾ��
DROP TABLE IF EXISTS `p_user`;
CREATE TABLE `p_user` (
`id` int(11) NOT NULL auto_increment,
`name` varchar(10) default NULL,
`sex` char(2) default NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `p_user` VALUES (‘1’, ‘A’, ‘��’);
INSERT INTO `p_user` VALUES (‘2’, ‘B’, ‘Ů’);
INSERT INTO `p_user` VALUES (‘3’, ‘C’, ‘��’);
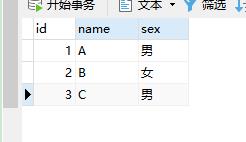
Ȼ��oname�ֶ΄���Unique������Ո���аٶȡ�
explain������C�����Ƿ���Ч
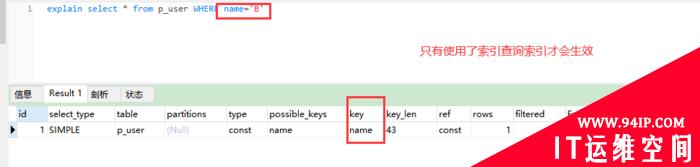
��һ����ʹ���б�name��ԃ��C������
1��ʹ�������Еr�����ŕ���Ч���Z�����£�
explain select * from p_user WHERE name=’B’
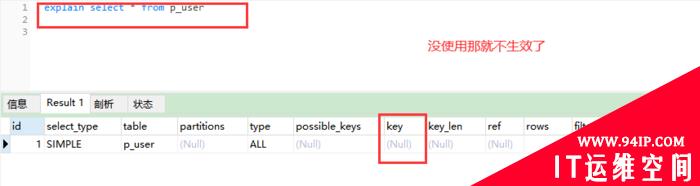
2����ʹ��������ԃ��
explain select * from p_user
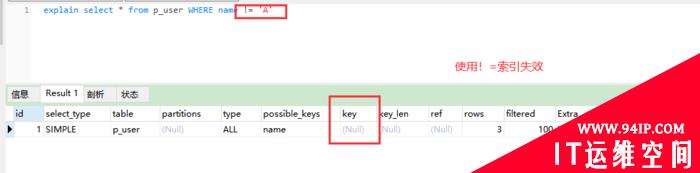
�ڶ�����ʧЧ��������
1��ʹ���Z�䣺
explain select * from p_user WHERE name != ‘A’
���������ͺψ�����
1��ʹ���Z�䣺
explain select * from p_user WHERE name=’B’ AND name != ‘A’
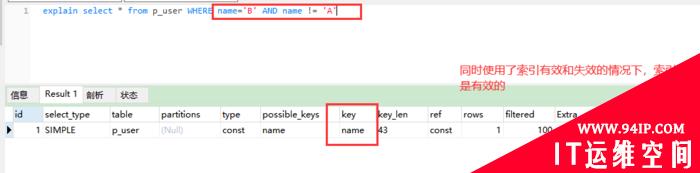
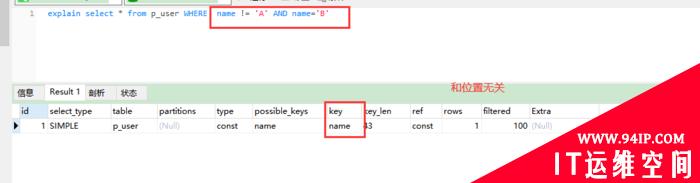
explain������B
explain�@ʾ��MySQL���ʹ��������̎��select�Z���Լ��B�ӱ��������Ԏ����x����õ������͌����������IJ�ԃ�Z��
explain�@ʾ�˺ܶ��У������P�I�ֵĺ��x���£�
- table�����˼�x���@ʾ�@һ�еĔ������P���ď����ģ�
- type���@����Ҫ���У��@ʾ�B��ʹ���˺ηN��͡�����õ������B����͞飺const��eq_reg��ref��range��indexhe��ALL��
- possible_keys���@ʾ���ܑ������@�����е������������գ��]�п��ܵ����������Ԟ����P�����where�Z�����x��һ�����m���Z�䣻
- key�� ���Hʹ�õ������������NULL���t�]��ʹ�����������ٵ���r�£�MySQL���x��������������@�N��r�£�������Select�Z����ʹ��USE INDEX��indexname���폊��ʹ��һ������������IGNORE INDEX��indexname���폊��MySQL����������
- key_len��ʹ�õ��������L�ȡ��ڲ��pʧ���_�Ե���r�£��L��Խ��Խ�ã�
- ref���@ʾ��������һ�б�ʹ���ˣ�������ܵ�Ԓ����һ��������
- rows��MySQL�J���횙z����Á�����Ո�����Д���
- Extra���P��MySQL��ν�����ԃ���~����Ϣ��
- ���w�ĸ��������ܱ�ʾ��ֵ�Լ����x���ԅ���MySQL�ٷ��ęn��B����ַ��https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
�������ʧЧ�Ĉ���
- where �Ӿ���ʹ�� != �� <> �����������挢�ŗ�ʹ���������M��ȫ����衣
- where �Ӿ���ʹ�� or ���B�ӗl��������������ŗ�ʹ���������M��ȫ����裬��ʹ�����Зl��������Ҳ����ʹ�ã��@Ҳ�Ǟ�ʲô�M������ or ��ԭ��
- ���ڶ�������������ʹ�õ�һ���֣��t����ʹ��������
- �����������ַ�������һ��Ҫ�ڗl���Ќ�����ʹ����̖������������t����ʹ��������
- like��ģ����ԃ�� % �_�^������ʧЧ��
- �� where �Ӿ��Ќ��ֶ��M�б��_ʽ��������������ŗ�ʹ���������M��ȫ����衣
- �� where �Ӿ��Ќ��ֶ��M�к�����������������ŗ�ʹ���������M��ȫ����衣
- �� where �Ӿ��е� “=” ��߅�M�к��������g�\����������_ʽ�\�㣬����ϵ�y�����ܟo�����_ʹ��������
- ���m���Iֵ�^�ٵ��У��؏͔����^����У�������������TYPE��5���Iֵ�������1�f�l��������ô WHERE TYPE = 1���L�����е�2000�������K���ټ�***�������K��һ��Ҫ�L������200���Ĕ����K�����ȫ����裬���O10�l����һ�������K����ôֻ���L��1000�������K����Ȼȫ������L���Ĕ����K��һЩ���϶��Ͳ������������ˡ�

